[asa myBook]B01K2VYSNG[/asa]
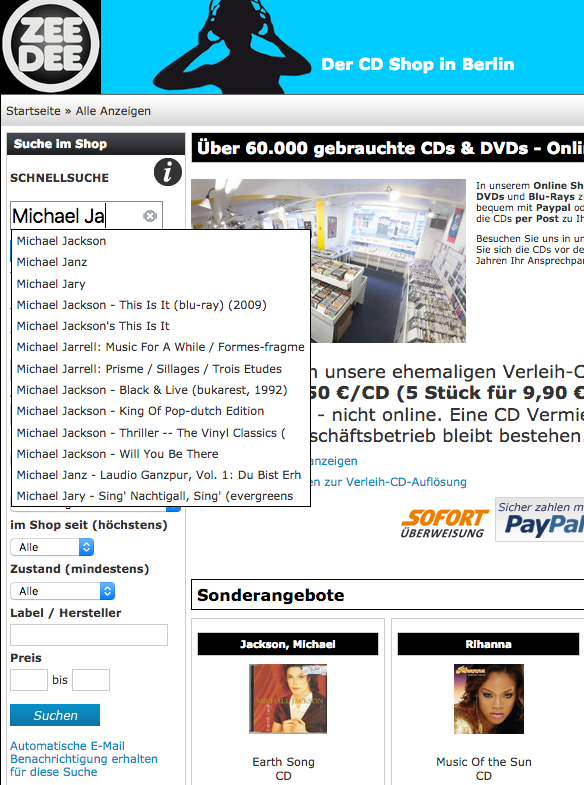
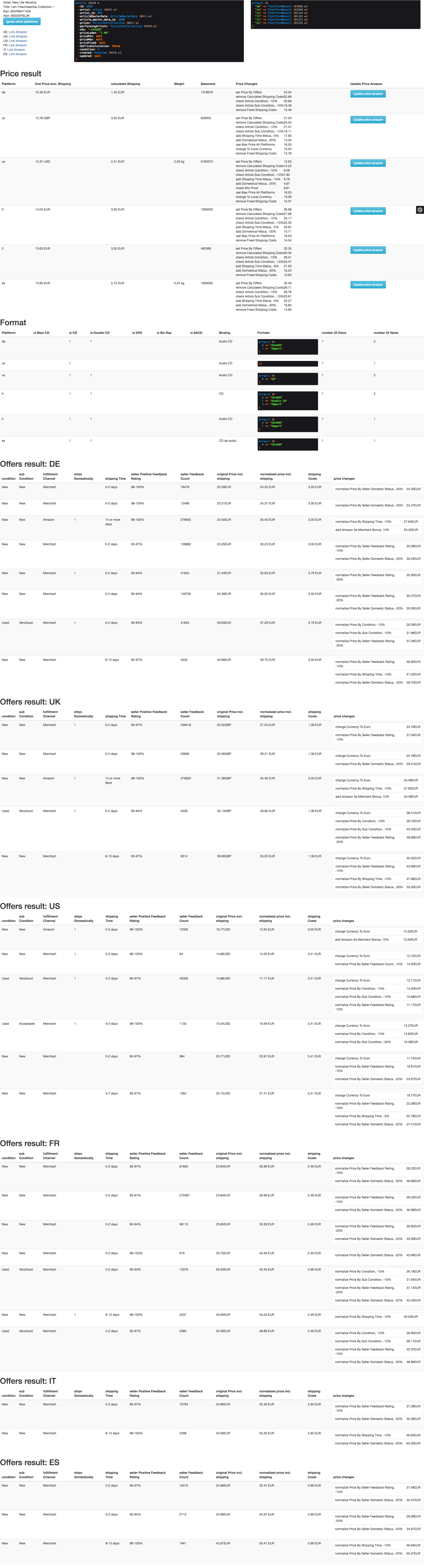
Elasticsearch macht den Einstieg nicht einfach, es ist hilfreich die folgenden Begrifflichkeiten zu verstehen.
Der Analyser
Ein Analyser berechnet die Daten für den Index vor und speichert das Ergebnis beim Aktualisieren der Daten einmalig ab. Aus dieser Menge an Tokens kann dann die Suche Ergebnisse ermitteln.
Ein Analyzer besteht aus 3 Teilen, die in der Reihenfolge angewendet werden:
1. Character Filter
– html_strip: Entfernt HTML Tags and dekodiert HTML Entitäten wie zum Beispiel &
– mapping: Ersetzt jedes Vorkommen eines Strings durch einen anderen
– pattern_replace character: Ersetzt mit Hilfe eines Regex jeden Treffer durch einen geeigneten
2. Tokenizer
– Ein Tokenizer berechnet aus einem String Tokens, d.h. einzelne Wörter und Wortgruppen
3. Token Filter
– ein Token Filter kann Tokens herausfiltern, die z.B: sehr kurz sind oder bestimmte Stop-Wörter wie „der“, „es“, „am“
Es gibt auch schon vorgefertigte Analyzer für den Anfang.
Wenn nur ein Analyzer angegen wird, dann wird dieser sowohl für die Indexierung, als auch für den Query-String verwendet. Es lassen sich unterschiedliche verwenden mit Hilfe von analyzer und search_analyzer.