Um alle Topics eines MQTT Brokers zu abonnieren und zu lesen reicht der Befehl aus (bei localhost, Port 1883):
mosquitto_sub -v -t '#'
oder bei nicht localhost und nicht standard Port:
mosquitto_sub -v -h BROKER_IP -p BROKER_PORT -t '#'
relationale Datenbanken, NoSQL und Caches
Um alle Topics eines MQTT Brokers zu abonnieren und zu lesen reicht der Befehl aus (bei localhost, Port 1883):
mosquitto_sub -v -t '#'
oder bei nicht localhost und nicht standard Port:
mosquitto_sub -v -h BROKER_IP -p BROKER_PORT -t '#'
Bei einem Kunden wurde mir folgende Fehlermeldung angezeigt, wenn ich versucht habe über Symfony die Datenbank erstellen zu lassen:
General error: 1709 Index column size too large. The maximum column size is 767 bytes.
Dies liegt daran, das Strato so komische Einstellung bei ihren Managed Hosting Packete wie z.B. das STRATO PowerWeb hat. Strato wird diese Einstellung leider nicht ändern, aber man kann in Symfony in der doctrine.yaml (config.yaml) das Charset ändern, dann funktioniert Symfony auch auf einem Strato Server:
doctrine:
dbal:
# configure these for your database server
driver: 'pdo_mysql'
server_version: '5.6'
charset: utf8
default_table_options:
charset: utf8
collate: utf8_general_ci
Das gerade fertiggestellt Projekt baby-taschenrechner.de beschäftigt sich mit den Fragestellungen rund um die Entwicklung des eigenen Kindes:
Die Webseite soll Eltern dabei helfen herauszufinden, wann sie welche Kleidergröße kaufen müssen, um im nahenden Winter/Sommer das passende zu Hause zu haben.
Eltern können so einschätzne, ob das Kind zu dünn oder zu dick ist für ihr Alter/Größe/Gewicht-Verhältnis.
Für die Realiserung wurden folgende Technologien verwendet:
Symfony 3, Docker, MySQL, PHP, GIT, Google Material Design, Amazon AWS
Um eine einfach HTTP basic authentication einzurichten für Elasticsearch mit Username und Passwort muss man als erstes X-Pack installieren.
Danach sollten alle Funktionen automatisch mit Basic Auth geschützt sein. Nach der Installation steht ein Default-User bereit, um weiterarbeiten zu können:
Name: elastic Password: changeme
Damit können dann erfolgreich Requests gemacht werden:
curl --user elastic:changeme -XGET 'localhost:9200'
Nun könnne eigene User hinzugefügt werden:
curl --user elastic:changeme -XPOST 'hlocalhost:9200/_xpack/security/user/SebastianViereck?pretty' -H 'Content-Type: application/json' -d'
{
"password" : "thePassword",
"roles" : [ "superuser"],
"full_name" : "Sebastian Viereck",
"email" : "email@sebastianviereckEmails.de",
"metadata" : {
"intelligence" : 7
},
"enabled": true
}
Danach können sofort Requests mit dem User gemacht werden:
curl --user SebastianViereck:thePassword -XGET 'localhost:9200'
Es sollten eigene Rollen angelegt werden und benutzt werden oder wie hier die vorgefertigten Rollen (superuser) benutzt werden.
Sehr wichtig: Natürlich muss der Default elastic User mit dem „changeme“ Passwort wieder deaktiviert werden. In der elasticsearch.yml muss dafür der folgende Parameter eingesetzt werden:
xpack.security.authc.accept_default_password: falseUnd der elasticsearch Service neugestartet werden:
sudo service elasticsearch restart
Zur Kontrolle sollte bei dem Request eine Fehlermeldung erscheinen:
curl --user elastic:changeme -XGET 'localhost:9200'
Es sollte unbedingt eine Daten-Verschlüsselung mit SSL benutzt werden.
Der IP Raum, mit dem überhaupt kommuniziert werden darf, sollte auch eingeengt werden.
Um den ELK Stack, bestehend aus:
auf Amazon AWS zum Testen auf einer einzigen Amazon EC2 Instanz zu installieren, kann man wie folgt vorgehen:
Man fährt eine EC2 Instanz hoch, die nicht zu klein ist, was den Ram anbelangt, mindestens eine m4.large mit 8GB Ram und 2 Prozessoren, da Elasticsearch schon gehobene Ansprüche an die Speicher stellt und auch Logstash sehr ressourcenhungrig ist. Als Betriebsystem habe ich Ubuntu-16 gewählt (ami-1e339e71).
Dann kann man eine Elastic-IP auf die Instanz legen, damit man die Instanzen unkompliziert austauschen kann und man trotzdem die IP weiter behält.
Wenn man ein Autocomplete mit Elasticsearch mit Realtime „Search-As-You-Type“ Funktionalität bauen will, bietet Elasticsearch ein sehr schnelles Completion Suggest an.
Das Problem ist, dass damit nur Ergebnisse erzielt werden können, die am Anfang des Strings liegen:
Ein Suche nach „Jackson“ findet nicht den Eintrag „Michael Jackson„. Oder eine Suche nach „Thiller Michael Jackson“ findet nicht „Michael Jackson Thriller„.
Die Lösung ist: Es ist schlichtweg nicht möglich mit dem Completion Suggest dies zu bewerkstelligen, da der Algorithmus dies nicht unterstützt.
Um trotzdem die passende Ergebnisse zu bekommen, habe ich die Daten für das Autocomplete über denselben Query, wie für die Suchergebnisse generiert. Dies ist zwar Performance mäßig schlechter, aber die Ergebnisse des Autocomplete und der Suchergebnisse nach dem Abschicken stimmen auf jeden Fall überein und iritieren den User nicht.
Elasticsearch macht den Einstieg nicht einfach, es ist hilfreich die folgenden Begrifflichkeiten zu verstehen.
Der Analyser
Ein Analyser berechnet die Daten für den Index vor und speichert das Ergebnis beim Aktualisieren der Daten einmalig ab. Aus dieser Menge an Tokens kann dann die Suche Ergebnisse ermitteln.
Ein Analyzer besteht aus 3 Teilen, die in der Reihenfolge angewendet werden:
1. Character Filter
– html_strip: Entfernt HTML Tags and dekodiert HTML Entitäten wie zum Beispiel &
– mapping: Ersetzt jedes Vorkommen eines Strings durch einen anderen
– pattern_replace character: Ersetzt mit Hilfe eines Regex jeden Treffer durch einen geeigneten
2. Tokenizer
– Ein Tokenizer berechnet aus einem String Tokens, d.h. einzelne Wörter und Wortgruppen
3. Token Filter
– ein Token Filter kann Tokens herausfiltern, die z.B: sehr kurz sind oder bestimmte Stop-Wörter wie „der“, „es“, „am“
Es gibt auch schon vorgefertigte Analyzer für den Anfang.
Wenn nur ein Analyzer angegen wird, dann wird dieser sowohl für die Indexierung, als auch für den Query-String verwendet. Es lassen sich unterschiedliche verwenden mit Hilfe von analyzer und search_analyzer.
Wenn das Auto-Completion Suggest Queries sehr langsam werden (beim mir um 1000ms = 1s), dann kann das daran liegen, dass contexts benutzt werden.
"titleSuggest": {
"type": "completion",
"contexts": [
{
"name": "contextName",
"type": "category",
"path": "path"
}
]
},
Ohne Context werden diese Queries wieder schneller um den Faktor 100 (10ms).
Das letzte Projekt war sehr spannend, es handelte sich um eine Erweiterung des PHP Shop-Systems namens XT-Commerce bzw. des Derivats SEO-Commerce um eine Suche aktuellem Standards für Zeedee Berlin.
Elasticsearch wurde auf einer eigene Amatzon MWS EC2 Instanz gehostet mit 1GB Ram und 1 CPU (sehr kostengünstig).
Die folgende Funktionalität kann ganz einfach wieder deaktiviert werden an zentraler Stelle, wenn es Probleme mit Elasticsearch gibt und die alte MySQL Suche tritt wieder in Kraft.
Beim Eintippen des Suchwortes werden schon Vorschläge gegeben im Millisekundenbereich. Dadurch kann der Kunde viel Zeit sparen und bei der Rechtschreibung wird auch geholfen. 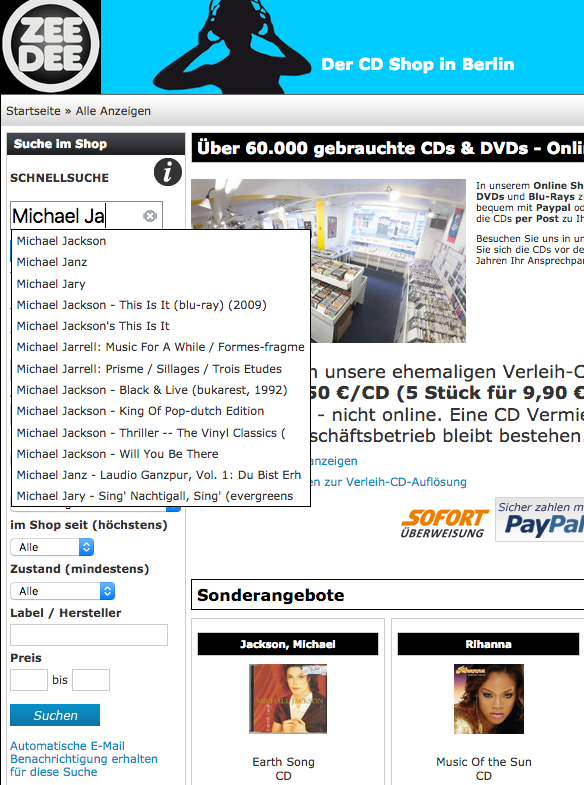
Mit der docker-compose.yml kann man sich schnell eine Container-basierte Umgebung mit Docker bauen. Anpassbar sind die Memory-Werte für die Java-VM (512MB) und für das Docker Image (1GB).
Um einen Cluster mit 2 Nodes zu betreiben, kann man die elasticsearch2 auskommentieren.
version: '2'
services:
elasticsearch1:
image: docker.elastic.co/elasticsearch/elasticsearch:5.4.1
container_name: elasticsearch1
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
mem_limit: 1g
volumes:
- esdata1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- esnet
# elasticsearch2:
# image: docker.elastic.co/elasticsearch/elasticsearch:5.4.1
# environment:
# - cluster.name=docker-cluster
# - bootstrap.memory_lock=true
# - "ES_JAVA_OPTS=-Xms512m -Xmx512m"
# - "discovery.zen.ping.unicast.hosts=elasticsearch1"
# ulimits:
# memlock:
# soft: -1
# hard: -1
# mem_limit: 1g
# volumes:
# - esdata2:/usr/share/elasticsearch/data
# networks:
# - esnet
volumes:
esdata1:
driver: local
# esdata2:
# driver: local
networks:
esnet: